Конференция Radeon.ru
| Страница 1 из 2 [ Сообщений: 57 ] Версия для печати [+] | На страницу 1, 2 След. |
Источник |
|
Пусть бросает
") |
|
Не добросит?
") |
|
Судя по описанию чипа, они скорее "бросают вызов" в сторону NetLogic.
|
|
Asmodeus, полагаю что реальная производительность упрется в конкурентный доступ к памяти и передачи по этой матрице, и результат будет куда как ниже, чем при простом суммировании производительностей ста ядер. Можно подобрать приложения, где выигрыш будет, — как раз, некоторые нетребовательные к производительности "облака", но это очень нишевое дело.
|
|
Stranger_NN
Судя по отзывам (предыдущее поколение), память и матрица там очень шустрые. Производительность в пару раз выше, чем у 4-х ядерного x86 процессора, при в разы меньшем энергопотреблении. Ну а нишевое дело само-собой разумеется — такие VLIW процы вставляются в свои железки, и для них пишутся свои программы. |
|
Где-то вроде бы читал, что там набор инструкций может меняться:
Типа того — дело в гибкости применения этих процессоров. Ну я вообще-то профан в этом вопросе — точно утверждать не буду. В любом случае — это лишь первые шаги данной компании, насколько я понял. И опять же — главный козырь — низкое энергопотребление при хорошей производительности и мощном параллелизме. Всё же, имхо, процессоры достойны отдельной ветки в форуме |
Это как сумма производительностей ядер? Запросто. Насколько часто удается распараллелить задачу на 100(!) потоков? Как решается проблема crossfire доступа к памяти? Я так понял эту фразу, как возможность организации MISD и MIMD конвейеров, — это очень интересно, но опять же довольно узкоспециально.  |
|
Asmodeus
Типа того — дело в гибкости применения этих процессоров. Ну да — гибко программируемый относительно микроконтроллеров. Можно сетевой трафик анализировать, можно видео перекодировать, но до гибкости процессоров общего назначения этому далеко. Примерно как современные GPU тоже гибкие, но в первую очередь заточены под вывод графики. Stranger_NN Это как сумма производительностей ядер? Запросто. Конечно. Насколько часто удается распараллелить задачу на 100(!) потоков? Скажем, надо проанализировать 100 независимых пакетов (NIC на 80 Гбит, как никак) — задача параллельна изначально. Как решается проблема crossfire доступа к памяти? Там на матрице к каждому ядру прилагается свитч. У каждого свитча есть пять двунаправленных соединений: к ядру и к свитчам вверх, вправо, вниз, и влево. Некоторые из крайних соединяются с контроллером памяти. Далее о внутренних сетях:
|
|
Buntar
Производительность в пару раз выше, чем у 4-х ядерного x86 процессора, при в разы меньшем энергопотреблении Причем, что интересно, никаких данных об этой "в разы более высокой производительности", просто нет Равно, как и нет результатов тестов Конечно, умозрительно вполне можно представить, где эта железка будет хороша. Но хотелось бы таки результатов замеров, а не просто разговоров Кстати сказать, Tilera претендует на ту же нишу, куда претендуют GPGPU: на высокопараллельные нагрузки. Но в лобовом столкновении с видеокартами эти процессоры проигрывают. Так что сомневаюсь я в их коммерческих успехах. Ну и гвоздь в крышку гроба: это не первая система Tilera. В прошлом году наши партнеры предлагали нам купить такую платформу от Tilera, еще со старыми ядрами. Цена здесь была бы под 30 килобаксов (!). Это в ситуации, когда сервер на интеловских процессорах стоит пару — тройку — пятерку килобаксов. В общем, удачи им. Она им понадобится.  |
|
matik
Равно, как и нет результатов тестов Синтетика есть тут: http://www.coremark.org/benchmark/index.php. Второе место, сразу за POWER7. Но я имел ввиду отзывы клиентов о производительности на их задачах. Это в ситуации, когда сервер на интеловских процессорах стоит пару — тройку — пятерку килобаксов. Тут мне кажется наиболее интересен прямой NIC-CPU интерфейс. На x86 приходится писать свой через NIC-DMA, т.к. то, что есть в ОС по умолчанию, не годится. Хотя, с другой стороны — уже есть себя зарекомендовавшие процессоры от NetLogic... |
А вот это — реально существенный довод против  Пожалуй даже самый главный и действительно смахивающий на "гвоздь в крышку гроба"  |
|
30 тысяч — это за один процессор или за корпус с восемью?
|
|
Buntar
30 тысяч — это за один процессор или за корпус с восемью? 30 тысяч — это за систему с несколькими сотнями ядер (прошлого поколения, это было до объявления новых ядер). Второе место, сразу за POWER7. Остался сущий пустяк: понять, что именно измеряет Coremark? Тут мне кажется наиболее интересен прямой NIC-CPU интерфейс. На x86 приходится писать свой через NIC-DMA, т.к. то, что есть в ОС по умолчанию, не годится Вообще-то в свое время АМД предлагала устанавливать любые специализированные сопроцессоры (хоть для сети, хоть для шифрования) прямо в процессорное гнездо, чтобы воспользоваться CPU интерфейсом Hyper Transport. Тогда и выяснилось, что это, в общем-то, мало кому нужно: пара компаний объявили какие-то продукты, но так это ничем и не кончилось. А ведь влияние АМД сильно поболее, чем у никому не известного стартапа. уже есть себя зарекомендовавшие процессоры от NetLogic... Во-во. Asmodeus А вот это — реально существенный довод против Пожалуй даже самый главный и действительно смахивающий на "гвоздь в крышку гроба" Дык! Собственно, как только нам обещают "революцию", всегда стоит спросить "почем?". Как правило, выясняется, что "овчинка выделки не стоит". |
|
Buntar, вам что-нибудь говорит термин "конкуренция за порт назначения"?
"Трехмерная" топология от нее все равно не спасает, если порт назначения ОДИН. И, кроме того, никакой производительности матрицы не хватит, если у процессора такого типа всего четыре канала памяти. Что на нем считать (учитывая небольшие кэши на самих ядрышках), бенчмарки по операциям регистр-регистр? |
|
matik
30 тысяч — это за систему с несколькими сотнями ядер (прошлого поколения, это было до объявления новых ядер). Подскажи, пожалуйста, где купить систему с 16-ю заполненными интеловскими сокетами за пару — тройку — пятерку килобаксов при цене одного процессора в пару — тройку — пятерку килобаксов? Остался сущий пустяк: понять, что именно измеряет Coremark? Название, в данном случае, говорящее — измеряет ядра без обвески в виде IO, памяти, или компилятора. Гугл пониманию должен помочь. Вообще-то в свое время АМД предлагала 1. Тут ОС можно хоть на каждом ядре запустить — процессор от АМД не нужен. 2. Да, рынок таких контроллеров относительно небольшой, миллиард-два. Stranger_NN вам что-нибудь говорит термин "конкуренция за порт назначения"? Вашему маршрутизатору действительно не хватает 4 x 64 бит каналов DDR3 памяти? Учитесь правильно писать. И это не x86, где всё должно идти через память или бессмысленно в неё копироваться. Что на нем считать (учитывая небольшие кэши на самих ядрышках), бенчмарки по операциям регистр-регистр? Подбирайте ядра под задачу. Автобус сотню простых людей перевезёт быстрее, чем 4-х местный люксовый седан, хоть и ездит медленнее. В данном случае задачи производителем конкретно названы: Network Infrastructure • Routers (SMB, enterprise, core) • Services blades (security offload, media services) Network Security • Firewall (SPI, proxy) • VPN appliances (IPsec, SSL) • Intrusion detection and prevention (IDS/IPS) • Data leakage prevention (DLP) Network Optimization • WAN optimizer (compression, data caching, de-duplication) • Server load balancer (SLB) • Network monitoring (flow tracking and deep packet inspection) Other: • Data Forensics and e-Discovery (Live Data Capture and Correlation) • Network Test Equipment (Wire-speed Packet Analysis & Generation) |
Маршрутизатору хватает. А вот SQL сервер с удовольствием потребит и вдвое больше — при том, что формально с x86 процессорами у него "в два раза ниже производительность". Да и веб-сервер с хорошей серверной частью при сотнях клиентов тоже выжрет столько ПСП, сколько сумеете дать. И еще попросит. Я читал сайт. Сколько там мегабайт кэша у каждого из ядрышек?  Ах, не мегабайты.... Тогда "см. п.1". Все опять упрется в работу с памятью. И мне не кажется, что пропускная способность памяти у него ниже, чем у сетевых интерфейсов в сумме? Ах, не мегабайты.... Тогда "см. п.1". Все опять упрется в работу с памятью. И мне не кажется, что пропускная способность памяти у него ниже, чем у сетевых интерфейсов в сумме? Единственное, где можно что-то придумать — это работа с опорой на встроенный сетевой интерфейс. Но и тут в реальных задачах я бы не ждал чудес по вышеизложенным причинам. Фактически, если медиа-сервер поднимать с односторонним потоком данных из памяти в сеть со сжатием по пути? Но у меня есть сомнения в достаточности производительности ядрышек для изохронной компрессии "на лету" хотя бы с низким качеством. А если сформировать из них, скажем, десять MISD-векторов для обработки потоков, — то в чем будет преимущество перед 12-ядерными "нормальными" процессорами (особенно в многосокетной системе) непонятно. В общем, очень узкоспециальная штука с крайне сомнительной перспективой. В свое время, если помните, были очень продвинутые сетевые адаптеры на 100mbps со своим процессором i960 на борту — давали уникально низкую загрузку процессора. Но потом появились процессоры P-II и эти суперсетевухи вымерли за ненадобностью. |
|
Buntar
Подскажи, пожалуйста, где купить систему с 16-ю заполненными интеловскими сокетами за пару — тройку — пятерку килобаксов при цене одного процессора в пару — тройку — пятерку килобаксов? Ну, если честно, то при необходимости большие бренды могут продавать четверки с ОЧЕНЬ существенными скидками. Скажем, процентов 80% Я такие случаи знаю.Да и для того, чтобы победить 800 тех дешевых ядрышек, никаких четырехпроцессорников не нужно: вон у микры есть 2U система с 4-я двухпроцессорными нодами. Итого — 8 процессоров класса Xeon 56xx в 2U. Она, скорее всего, в большинстве случаев будет сильно быстрее Название, в данном случае, говорящее — измеряет ядра без обвески в виде IO, памяти, или компилятора. Гугл пониманию должен помочь. Гугль пониманию нифига не помог Потому что элементарная производительность ядер (без влияния всего остального) есть прямо в документации (в разделах "темп и пропускная способность инструкций") А реальных ядер и реальных задач без влияния обвески не бывает. Так чем здесь должен помочь гугль? Тут ОС можно хоть на каждом ядре запустить — процессор от АМД не нужен Угу. А потом все эти ОС полезут в общую память. Толково Да, рынок таких контроллеров относительно небольшой, миллиард-два. Это в штуках, что ли? Ну, ежели по 1 центу, можно и продать миллиард — другой. Потому что я ну никак не понимаю, зачем в роутере или холодильнике такая песня. Там обычных MIPS\ARM хватает, производительности особой никто не ждет, да и как это чудо программировать — тоже нифига не понятно. Зачем оно? |
|
Stranger_NN
А вот SQL сервер с удовольствием потребит и вдвое больше — при том, что формально с x86 процессорами у него "в два раза ниже производительность". А причём тут SQL? Вы бы ещё игрушку какую-нибудь в пример привели и на отсутствие FPU посетовали. Речь о производительности шла при использовании процессора по назначению, вообще-то. Причем, не "в два," а "в пару раз" — разница больше, чем в два раза. Да и веб-сервер с хорошей серверной частью при сотнях клиентов тоже выжрет столько ПСП, сколько сумеете дать. И еще попросит. Они скоростью сети ограничены. И мне не кажется, что пропускная способность памяти у x86 ничуть не выше (те же 4 x 64 бит DDR3), чем у здесь обсуждаемых? Я читал сайт. Cloud Computing? ХЗ. Пока я видел только отзывы об их использовании в сетевой структуре или для видео I/O по сети.И мне не кажется, что пропускная способность памяти у него ниже, чем у сетевых интерфейсов в сумме? Сеть — 80 Gbps, ПСП — ~500 Gbps. Но у меня есть сомнения в достаточности производительности ядрышек для изохронной компрессии "на лету" хотя бы с низким качеством. 2008 год: The TILE64 processor can handle up to eight HD 1080P streams processing encode at 30 frames-per-second. И по отзыву пользователя тоже всё замечательно. то в чем будет преимущество перед 12-ядерными "нормальными" процессорами (особенно в многосокетной системе) непонятно. ~20 Вт против ~100 Вт. В свое время, если помните, были очень продвинутые сетевые адаптеры на 100mbps со своим процессором i960 на борту — давали уникально низкую загрузку процессора. Но потом появились процессоры P-II и эти суперсетевухи вымерли за ненадобностью. Не вымерли они. Вот, собственно, x86 конкурент сабжу: IBM Proventia Network Intrusion Prevention System (IPS) GX6116
Стоят они как раз под тридцать тысяч. matik Ну, если честно, то при необходимости большие бренды могут продавать четверки с ОЧЕНЬ существенными скидками. Думаешь, к Tilera это почему-то не относится? Сам процессор меньше тысячи стоит. Я всё к тому, что нет особой разницы в цене. Она, скорее всего, в большинстве случаев будет сильно быстрее Тоже, видимо, какой-нибудь SQL или SAP имеешь ввиду? Больше 6 Gbps трафика через x86 в 2U я не встречал. Потому что элементарная производительность ядер (без влияния всего остального) есть прямо в документации (в разделах "темп и пропускная способность инструкций") Ты писал про отсутствие результатов тестов. Я же написал: "синтетика." Как их ещё тестировать — в реальности у всех свои программы, и задачи, и железо? А реальных ядер и реальных задач без влияния обвески не бывает. Так чем здесь должен помочь гугль? Ну вот ещё пара тестов из Гугла: http://www.tilera.com/about_tilera/pres ... nce-10gbps
http://www.bdti.com/InsideDSP/2008/09/17/Tilera
Угу. А потом все эти ОС полезут в общую память. Толково Можно не значит нужно. Это в штуках, что ли? В американских долларах. NetLogic Microsystems Begins Revenue Shipments of its XLP® Multi-Core Processor into $1.5B Control Plane Market Там обычных MIPS\ARM хватает Разве что в домашней мыльнице. производительности особой никто не ждет От сети?  да и как это чудо программировать — тоже нифига не понятно. Зачем оно? Чтоб интернеты и вконтактики работали. |
|
Поглядел я на это чудо и вспомнил KSR1/KSR2. Правда, те вообще без памяти работали (COMA), а масштабируемость была покруче. 20 лет назад дело было, первые 64-битные процессоры и всё такое. Плохо закончили.
|
|
Buntar
И мне не кажется, что пропускная способность памяти у x86 ничуть не выше (те же 4 x 64 бит DDR3), чем у здесь обсуждаемых? Сильно больше, вообще говоря. У двушек нынешних — 3 х 64 бита у каждого процессора (6 х 64 бита на систему), у вот-вот выходящих двушек — 4 х 64 бита х 1600МГц на каждый процессор. При этом реально достижимая ПСП у х86 тоже выше. ~20 Вт против ~100 Вт. Это лукавое сравнение Потому что в реальности будет сравниваться система на 1кВт против системы на 1.1кВт Сам процессор меньше тысячи стоит Это ОЧЕНЬ много. Обычные Хеоны стоят пару — тройку сотен (кроме старших), меньше тысячи при определенных условиях можно четырехпроцессорные камни купить. А АМД так вообще разницы не делает между двушками и четверками (в цене процессоров). Вот и попробуй объяснить, чем 36 тупых медленных ядер лучше, чем 16 быстрых в Оптероне 62хх Тоже, видимо, какой-нибудь SQL или SAP имеешь ввиду? Как раз SQL или SAP на Tilera еще, возможно, неплохо побегают (они умеют прилично распараллеливаться на большое количество ядер). А вот всяческие эксченджи\лотусы\шарепоинты\прочая корпоративная фигня — тут Tilera просто со свистом пролетает. Как их ещё тестировать — в реальности у всех свои программы, и задачи, и железо? Да понятно, что либо синтетикой, либо реальными программами. Но если синтетикой — то четко понимать, что за алгоритм мы проверяем. Так вот, что за алгоритм в CoreMark-е, и насколько он хорошо оптимизирован под разные архитектуры — совершенно неясно. А без этого понимания результат — чистой воды попугаи. Можно не значит нужно. А какие ты знаешь ОС, которые НЕ лазят во внешнюю память? Я вот как-то затрудняюсь что-то сказать Разве что в домашней мыльнице. Да и не в домашней уже: два ядра по 2ГГц у нынешних ARMов (например, Самсунговского Exinox 5210) — уже вполне пристойный чип. И если уж х86 кого-то бояться, то скорее АРМов. От сети? Слушай, у меня в гигабитном роутере чип MIPS на 480MHz. Средняя загрузка — около 3%. Что мне надо сделать на роутере, чтобы мне понадобилась там Tilera? Чтоб интернеты и вконтактики работали. Они отлично работают на х86 и на цисках. Должна быть внятная причина для полной смены оборудования. Я ее пока не вижу: финансы примерно те же, область применения сильно уже, требует кардинальной переработки большинства имеющегося ПО. Не, не в этой жизни. |
Да нет, я знаю что говорю — именно SQL (а так же другие БД с множественными запросами — DNS, роутинг и так далее), как сильно параллелящаяся задача, особенно при многопользовательской загрузке — идеальнее всего ложится на эту структуру. Но тут упрется в ПСП, причем относительно даже недорогой двухсокетной х86 платформы. Которая в итоге уделает 64 и даже 100-ядерную такую систему как Тузик грелку. А с учетом многомегабайтовых кэшей — даже и говорить не о чем.Заметьте, не я придумал про кодирование видео по сети.  Фактически, это единственное, где можно что-то придумать архитектурно красивое из этого процессора для не очень сильно специальных задач. Фактически, это единственное, где можно что-то придумать архитектурно красивое из этого процессора для не очень сильно специальных задач. Рискну предположить, что 64-ядерный процессор превращен в восемь MISD конвейеров — тогда да, вполне допускаю достижение такого результата. Но, простите, за 30 тысяч долларов я из х86 систем соберу систему потокового кодирования на несколько десятков потоков. Отказоустойчивую. Одноюнитовый узел с двумя Intel Xeon X5650 и 24GB памяти (два БП и два винта в зеркале) — $5к, NAS N8800SAS с 6*300 — еще $6-7k, два ИБП и гигабитовый свитчик хороший — ну, пускай еще $5k, Итого, за $30k имеем: четыре ноды (8 процессоров и 192 гигабайта памяти на ДВЕНАДЦАТИ каналах DDR3), NAS с SAS, питание и сетевое оборудование. Погоняемся с этим одиночным монстром за $30k (его еще надо дополнить стораджем и ИБП, так что у меня еще есть на пару нод форы — так что берите ШЕСТЬ вышеописанных серверочков, или InfiniBand/10GBe структурку внутре кластера)?  У вас есть сомнения в результате на ЛЮБОЙ мыслимой задаче? И разница тут будет не на проценты, а во многие разы.Уже ответили. В потреблении серьезного сервера доля процессора невелика. Это все? Это совсем другое устройство. Я имел в виду PCI сетевухи со своими процессорами и довольно мощным API в обычные х86 серверы. Они самостоятельно работали с памятью и брали на себя чуть ли не третий уровень OSI, разгружая CPU. Иметь сотню-другую тысяч пользователей, полагаю. Это для ОЧЕНЬ больших роутеров. Но там пока вроде тоже особых напрягов нет и при существующих процессорах. |
|
Walter S. Farrell
Поглядел я на это чудо и вспомнил KSR1/KSR2. Правда, те вообще без памяти работали (COMA), а масштабируемость была покруче. Угу. |
|
matik
Сильно больше, вообще говоря. У двушек нынешних — 3 х 64 бита у каждого процессора (6 х 64 бита на систему), у вот-вот выходящих двушек — 4 х 64 бита х 1600МГц на каждый процессор. Так меньше ведь. У Tilera до 4 х 64 бита х 1866 МГц на разъём. На два разъёма будет 8 x 64 бита. На восемь аж 32 x 64. При этом реально достижимая ПСП у х86 тоже выше. При этом реально нужная ПСП у Tilera гораздо ниже — и по топологии системы, и по архитектуре процессора там память только боком, а не в центре:
Данные находятся в кеше, а копирование во внешнюю память опционально. Заявленная внутренняя ПС процессора:
Это лукавое сравнение Потому что в реальности будет сравниваться система на 1кВт против системы на 1.1кВт Что же тогда во всех обсуждениях серверных AMD vs Intel потребление идёт первым-вторым пунктом? И что же Atom'ы(!) в серверах пробуют? Сейчас даже обсуждение стоимости СО стало актуальным. О числах:
8-ми процессорная 2U — 400 Вт. Сколько на 16 x86 энергии и охлаждения надо? Это ОЧЕНЬ много. Обычные Хеоны стоят пару — тройку сотен (кроме старших), меньше тысячи при определенных условиях можно четырехпроцессорные камни купить. А мы разве бюджетное железо обсуждаем? Вот и попробуй объяснить, чем 36 тупых медленных ядер лучше, чем 16 быстрых в Оптероне 62хх Продолжаю пробовать. О тупых медленных ядрах см. Coremark выше. 16 ядер Бульдозера вдруг стали быстрыми? Добавь сюда нужду в ПСП и в гигантских кешах у x86, отсутствие прямого NIC-CPU интерфейса, потребление. А вот всяческие эксченджи\лотусы\шарепоинты\прочая корпоративная фигня — тут Tilera просто со свистом пролетает. А Tilera туда свои процессоры предлагает? Так вот, что за алгоритм в CoreMark-е, и насколько он хорошо оптимизирован под разные архитектуры — совершенно неясно.
Напр., с CRC я по своей работе очень близко знаком (вижу и использую каждый день, многократно). Никто свой алгоритм не пишет — на любой архитектуре любым производителем используется один и тот же кусок кода, написанный в C. Даже свой проприетарный аналог (назвали CDCK) мы сделали, только маленько изменив этот кусок кода. Теперь о C компиляторах:
А без этого понимания результат — чистой воды попугаи. Чистой воды попугаи производители в даташитах пишут. Ага. А какие ты знаешь ОС, которые НЕ лазят во внешнюю память? Внешняя память там есть. Отдать даже полдюжины ядрышек и кусочек прочих ресурсов на обслуживание ОС совсем не проблема. И если уж х86 кого-то бояться, то скорее АРМов. Которых (64-битных ARM'ов) так и нет. Что мне надо сделать на роутере, чтобы мне понадобилась там Tilera? Загрузить его работой. Они отлично работают на х86 и на цисках. Случаем, не циски ли вкладывают в компанию Tilera деньги? О вконтактиках и x86:
Ну а в интернетах (BGP и т.п. протоколы) x86 вообще не конкурент, разница в производительности будет во многие разы. требует кардинальной переработки большинства имеющегося ПО Перекомпилировать ПО не проблема. Тем, кто сидят на DSP или FPGA работы будет больше, но для большой компании это тоже не проблема. Stranger_NN Но тут упрется в ПСП, причем относительно даже недорогой двухсокетной х86 платформы. Тут по топологии данные идут через процессор насквозь, память сбоку в качестве доп. буфера. На x86 идут сначала в память, потом копируются в кеш процессора, потом обратно в память. Которая в итоге уделает 64 и даже 100-ядерную такую систему как Тузик грелку. А 800-ядерную? Давайте либо сравнивать процессор с процессором, либо систему с системой. А с учетом многомегабайтовых кэшей — даже и говорить не о чем. Не от лёгкой жизни они там многомегабайтовые. Ну и в Tilera сумма кешей тоже несколько мегабайт, кстати. Но, простите, за 30 тысяч долларов я из х86 систем соберу систему потокового кодирования на несколько десятков потоков. 1. Это всё в одном 400 Вт 2U корпусе? 2. $5k * 4 + $6k + $5k = $31k. В 30 тысяч, названные matik'ом, скорее всего уже всё (сторадж и т.п.) входит. С софтом совсем не ясно. 3. Видео кодировать вообще лучше на GPU — там многое "железом" делается. Пользователю интереснее были сниженные сетевые задержки интерфейса. 4. $31k+ — это стоимость компонентов, а не системы. Вы за бесплатно работаете? И софт сам собой напишется (в моём понимании, система — это большей частью именно софт)? Уже ответили. В потреблении серьезного сервера доля процессора невелика. Это все? Я тоже уже в других местах в этой теме писал. Это совсем другое устройство. Именно такие устройства применительно к процессорам Tilera я изначально и имел ввиду. Я имел в виду PCI сетевухи со своими процессорами и довольно мощным API в обычные х86 серверы. Они самостоятельно работали с памятью и брали на себя чуть ли не третий уровень OSI, разгружая CPU. Я понял. Странновато Тилеру, то ли процессор, то ли микроконтроллер, позиционировать в обычные серверы. Но из этого обсуждения выяснилось, что не так уж и странно. В IBM Proventia сетевуха берёт первые четыре уровня, два x86 процессора только на последние три используются. Но там пока вроде тоже особых напрягов нет и при существующих процессорах. Интеловские XScale (ARM архитектура) до 10-ти гигабит дают, на x86 ещё меньше. |
Ммммм... Вы про SQL-запрос и его обработку? Тогда это немного не так. Запрос приходит по сети, обрабатывается процессором в оперативной памяти (в идеале) после чего полученная в результате обработки порция данных отправляется обратно по сети. Кстати. Я долго фтыкал в архитектуру, но так и не понял каким образом происходит обращение к памяти, находящейся на контроллере соседнего сокета? Как работает многосокетная система? Через высокоуровневый API, подобный применяемому в МРР системах по сетевым или PCI-E каналам i/o? Тогда это будет слабосвязанная система со всеми вытекающими ограничениями и проблемами. Перечислять? На сайте нет ни одного(!) примера многосокетных систем, максимум — PCI-E платы, которые могут общаться между собой через эту шину. Даже предположив, что это будет пассивный backplane — про низкую латентность и высокую среднюю ПСП, хотя бы отдаленно сопоставимую с таковыми параметрами классических х86 систем и говорить не приходится. Вообще. Я не зря нарушил порядок ответов... Дело в том, что в многомегабайтовые кэши позволяют "прожевать" некоторую часть кода и данных без обращения к ОЗУ, снижая тем самым нагрузку на оперативную память. Фактически, это "не от хорошей жизни" сделано для компенсации недостаточной ПСП и снижения латентности. А тут, внезапно, стало ПСП хватать. При якобы, "вдвое большей производительности" без таких продвинутых механизмов работы с ОЗУ... Противоречия не находите в этих утверждениях? Тем более, что "сумма кэшей" в несколько мегабайт не поможет — в пересчета на ядро (и исполняемый код) получается по чуть-чуть (320кб на ядро, при том, что мегабайта сейчас уже бывает маловато иногда), так что в память ядрам придется залезать постоянно и с хорошим темпом. "Размер имеет значение", если размер кэша много меньше локальности по коду и данным — то его роль в снижении нагрузки на память очень и очень невелика. Размеры данных и кода у SQL весьма и весьма, знаете-ли, — поэтому возвращаемся немного назад, к оценке работы SQL сервера на этой архитектуре. Упремся в ПСП и crossfire, к гадалке не ходи. Лучше деньги с деньгами, не находите? Я нормировал системы по затратам — и получается, что для Tilera ни SQL, ни видеокодирование — экономически обоснованными применениями не являются. ЗА ватты не скажу, но давайте в корпус попытаемся влезть (хотя в одном корпусе отказоустойчивость — нонсенс). — 4 x AMD Opteron 6172 2.1 (12MB, 12C) — 48 ядер при 48 мегабайтах кэша. — 16 х DDR3 4GB (1333 ECC) — шестнадцать каналов памяти и 64 гигабайта. — 6 х 500GB SATA на SAS HBA LSI 2008E SAS — 2 х Intel x520-da2 Dual Port 10GbE — четыре канала 10Gbe. — Дублированный БП 1400Вт — ПО — можно использовать бесплатное, благо платформа неспецифическая, монополии на подходящее к ней ПО нет. В отличие от. Итого: 459,000р ($15.3k по курсу ЦБ РФ). Причем(!), это стоимость СОБРАННОЙ системы с трехлетней гарантией, а не просто "сумма компонентов". matik не даст соврать, прикидывал по конфигуратору его конторы. Погоняемся на SQL или кодировании видеопотоков? Тем более, что если вернуться к нормированию по деньгам — то я могу "удвоиться". И получить, кстати, отказоустойчивость. Первый же промежуточный роутер и даже store-and-forward Ethernet коммутатор (а их, замечу, 99.99%, "on fly" работают только специализированные для кластеров, за нереальные деньги — но и они только в благоприятных по нагрузке ситуациях) сведет этот выигрыш к таким эфемерным величинам, что овчинка не будет стоить выделки. Совсем.  Не просто "не странно", но и абсолютно экономически невыгодно. Для получения сопоставимой производительности на классических задачах в Tilera серверы придется вложить во много раз больше денег, чем в классические х86 серверы. Причем, это в случае идеального распараллеливания нагрузки. В случае же неполной загрузки системы (скажем, тяжелыми запросами последовательной природы — но не 100 штук, а 10-20 разом), ситуация становится весьма печальной для новинки. Более того, это ЕДИНСТВЕННОЕ возможное к придумыванию разумное применение — тяжелые корневые маршрутизаторы с огромным трафиком. Но и то, с современными решениями ПОКА тягаться Tilera не может. Пускай вкладывают, может и родится что-то стоящее внимания — и потраченных денег. Да? А кто внутре у вот таких вот аппаратиков? |
|
Stranger_NN
Ммммм... Вы про SQL-запрос и его обработку? Тогда это немного не так. Не про SQL, конечно. Я про Snort, например. Пакет идёт из сетевухи прямо в кеш ядра, куда он полностью влезает, оттуда после анализа идёт прямо снова в сетевуху, в оперативную память никогда не копируется, и использованная ПСП — ноль (результат анализа я тут не считаю). Та же задача, но на x86: из сетевухи через DMA пакет идёт в память; оттуда копируется в кеш процессора; потом снова идёт в сетевуху из оперативной памяти через DMA. Кстати. Я долго фтыкал в архитектуру, но так и не понял каким образом происходит обращение к памяти, находящейся на контроллере соседнего сокета? Как работает многосокетная система? Эти ноды независимы. Я не зря нарушил порядок ответов... Дело в том, что в многомегабайтовые кэши позволяют "прожевать" некоторую часть кода и данных без обращения к ОЗУ, снижая тем самым нагрузку на оперативную память. Не нужны многомегабайтовые кэши, когда многокилобайтовые уже "прожёвывают" весь код и данные, без обращения к ОЗУ. Противоречия не находите в этих утверждениях? Извините, я даже перечитал все свои посты в этой теме — никакого противоречия не нашёл. А вот у Вас каша какая-то:
Это не SPARC, и быть им не претендует. По крайней мере, я ничего подобного не писал. Тем более, что "сумма кэшей" в несколько мегабайт не поможет — в пересчета на ядро (и исполняемый код) получается по чуть-чуть (320кб на ядро, при том, что мегабайта сейчас уже бывает маловато иногда), так что в память ядрам придется залезать постоянно и с хорошим темпом. Тут эта сумма кэшей в качестве L3 работает, одни и те же данные на каждое ядро или ещё куда-либо не копируются. "Размер имеет значение", если размер кэша много меньше локальности по коду и данным — то его роль в снижении нагрузки на память очень и очень невелика. Т.е. плохие вещи происходят, если прибор не по назначению использовать. Размеры данных и кода у SQL весьма и весьма, знаете-ли, — поэтому возвращаемся немного назад, к оценке работы SQL сервера на этой архитектуре. Но ведь настолько нужна оценка работы SQL сервера на этой архитектуре! Лучше деньги с деньгами, не находите? 1. Массовая продукция всегда стоит дешевле. Была бы Tilera массовой, было бы дешевле. 2. GX6116 стоит столько же, а всего 6 Gbps. 3. Если сами хотите собрать конкурента на x86, за сколько Вам обойдутся 4 "Raza Microelectronics network processing unit (NPU) specifically designed for high-speed processing of network packets" (т.е. 32 cores @1.2 GHz)? хотя в одном корпусе отказоустойчивость — нонсенс Его в воду кидать что-ли? Восемь независимых нодов, two 1100W high efficiency redundant PSUs, 24 x H/S SATA HDD Trays. И нет причин одним корпусом ограничиваться — я имел ввиду в плане занимаемого этим всем места. 4 x AMD Opteron 6172 2.1 (12MB, 12C) — 48 ядер при 48 мегабайтах кэша. 8 x 100 ядер при 45 МБ кэша. 16 х DDR3 4GB (1333 ECC) — шестнадцать каналов памяти и 64 гигабайта. 32 канала и 256 ГБ. ПО — можно использовать бесплатное Оно есть? Тем более, что если вернуться к нормированию по деньгам — то я могу "удвоиться". Так "удваиваться" уже пора, мне кажется. Да? А кто внутре у вот таких вот аппаратиков? ASIC'и:
|
Ок. СУБД и все с ними связанное отбрасываем, получается? В т.ч. и веб-сервисы, которые сейчас в большинстве своем строятся как интерактивные СУБД тоже. Ок, едем дальше... Хм. Предполагаете, что анализ трафика по тысячам и тысячам признаков можно провернуть не обращаясь к оперативной памяти? Я вас разочарую. Банальные наборы вариантов, на совпадения с которыми надо проверить каждый из пакетов просто не поместятся (вместе с кодом) в кэш-памяти размером в 256-320кб. Так что без подкачки из ОЗУ не обойтись. Но, как и в случае с видеокодированием можно организовать несколько MISD векторов для проверки пакетов с повышенным быстродействием. И писать в память нужно самый мизер при этом, так что некоторые шансы в данном применении есть. Но и то, не упремся ли....? Ага. Значит я правильно понял. Т.е., "800-ядерной" системы не существует в природе. И любые прямые сравнения с сильносвязанными системами слегка некорректны. Это на каких задачах??? Потоковое видеокодирование, часть анализа трафика (далеко не вся задача) — что еще? Рост кэшей в универсальны процесорах оттого и попер, что "многокилобайтовых" глобально не хватало. Я еще не забыл ситуаций, когда 512кб на половинной скорости оказывалось сильно лучше 256кб полноскоростного кэша — а ведь это было уже почти 15 лет назад. С тех пор собачка могла подрасти программы распухли. Сильно. Вы не писали, согласен. Но почитайте название темы. Теперь вы согласны, что ни о каком "вызове в серверном сегменте" речи нет и быть не может? Это, простите, как? Персональные задачки ядер полностью помещаются в их кэши? А зачем тогда вообще четыре канала памяти тогда? Противоречие, однако...
Как я уже говорил, слабосвязанную систему нелья рассматривать в качестве прямого конкурента сильносвязанной. Банально: как будет выглядеть работа вашей машины с восемью модулями на одной несчастной PCI-E 16x — если десяток пользователей одновременно захотят изменить одни и те же данные? Причем, пользователи зашедшие на разные модули? А если потребуется обмен данными между модулями в параллельно считаемой задаче? Для обычных компьютеров? А чего вам не хватает?  Ага. Теперь расскажите, зачем мне нужды процессоры меньшей суммарной пропускной способности? Да, они более гибкие и позволяют — в перспективе — рисовать красивые архитектуры мощных маршрутизаторов. Но и только. Но, конечно, о "вызове в серверном сегменте" говорить не просто рано, но и бессмысленно. Глобально. |
|
Stranger_NN
Предполагаете, что анализ трафика по тысячам и тысячам признаков можно провернуть не обращаясь к оперативной памяти? Я вас разочарую. Банальные наборы вариантов, на совпадения с которыми надо проверить каждый из пакетов просто не поместятся (вместе с кодом) в кэш-памяти размером в 256-320кб. В случае простого анализа и т.п. (не по тысячам и тысячам признаков) вполне можно провернуть всё даже не выходя за рамки L2 кеша. Про непростые случаи см. L3 и ПСП. Ага. Значит я правильно понял. Т.е., "800-ядерной" системы не существует в природе. Ну пока нет, сотней ядер ограничивается. Будут 1000 ядер в одном чипе, будет и система. Причём, с очень сильно связанными ядрами. Но почитайте название темы. Теперь вы согласны, что ни о каком "вызове в серверном сегменте" речи нет и быть не может? О названии темы см. мой первый пост в этой теме. Это, простите, как?
А зачем тогда вообще четыре канала памяти тогда? Противоречие, однако... Я же писал, что ПСП высокая ("очень шустрые"). Как я уже говорил, слабосвязанную систему нелья рассматривать в качестве прямого конкурента сильносвязанной. На x86 сейчас имеем до 4 разъёмов x 16 ядер (Opteron 6200) = 64 более-менее связанных ядер, или до 8 разъёмов x 10 ядер (Xeon E7-8800) = 80 более-менее связанных ядер — дальше расширять тоже только по сети. А тут до 100 сильносвязанных ядер. И PCIe у Tilera только до 8x. Для обычных компьютеров? А чего вам не хватает? Вам что-то мешает запустить бесплатное ПО для обычных компьтеров на Tilera? А для необычных бесплатного ПО не бывает нигде — либо своё пишут, либо оно далеко не бесплатно. Теперь расскажите, зачем мне нужды процессоры меньшей суммарной пропускной способности? Да, они более гибкие и позволяют — в перспективе — рисовать красивые архитектуры мощных маршрутизаторов. Разработку и производство отдельных ASIC'ов под каждую задачу далеко не каждая компания может себе позволить. Особенно, если требуемое их количество мало — куда дешевле купить процессоры типа Тилеры и написать программу. Ну и про время написания в C vs Verilog я тут ссылку уже давал. Также, найти толкового Verilog-инженера очень трудно, и они все уже заняты. Но, конечно, о "вызове в серверном сегменте" говорить не просто рано, но и бессмысленно. Глобально. Угу. |
|
>Рост кэшей в универсальны процесорах оттого и попер, что "многокилобайтовых" глобально не хватало.
Рост попёр от того, что имелось много "лишних" транзисторов. Загнать 2Мб кэш-памяти в ядро Интел мог ещё при 180нм, но цена вопроса была такова, что дальше тяжёлых серваков дело не пошло. Мэйнстрим обходился скромными 256Кб. При 65нм "бюджетной" площади было достаточно уже для пары ядер и тех же 2Мб кэш-памяти. Как известно, каждое последующее удвоение кэш-памяти приносит эффект в разы меньше. Транзисторы загоняют в кэш только тогда, когда все остальные методы повышения производительности исчерпаны. >Я еще не забыл ситуаций, когда 512кб на половинной скорости оказывалось сильно лучше 256кб полноскоростного кэша — а ведь это было уже почти 15 лет назад. ПСП тогда была совсем смешная по современным меркам. Одноканальная PC100 или PC133 SDRAM, разгонять толком некуда, теоретическая ПСП 1ГБ/с. Сейчас массово доступна DDR3 PC3-12800, а для разгона можно купить PC3-18600 с теоретической ПСП почти 20ГБ/с. И это на каждый канал. |
Честно говоря, я плохо представляю себе сочетание режимов кэширования в такой системе. Получается очень много накладных расходов. Даже нет уверенности в том, что овчинка стоит выделки. Угу, 100 сильносвязанных. Только слабеньких ядер-то. Какой смысл "гнать счет", если итоговая производительность 100-ядерной системы (чисто арифметически просуммированная и на большинстве алгоритмов труднодостижимая) всего в два раза больше чем у неустановленного конкурента из мира х86? Грубо говоря, двухсокетная система х86 всегда будет не медленнее по арифметическому суммированию операций регистр-регистр и быстрее за счет большего количества каналов памяти. Кстати, в 1000 ядер я что-то не очень верю, необходимая пропускная способность коммутирующей матрицы нужно будет увеличить даже не в 10 раз относительно текущей реализации, а раз, эдак, в 100.... Если не в 1000. Это реально? Явно нет, а значит простое наращивание количества ядер не приведет к пропорциональному росту производительности. Хуже того, производительность отдельно взятого ядра будет произвольным образом меняться в зависимости от особенностей нагрузки на матрицу в данный момент времени. Нет. Брутфорс не рулит. Некоторая неоптимальность имеющегося ПО и сомнительная совместимость с архитектурой. А так ничего, да.... На не оптимизированном для этой необычной архитектуре коде реальная производительность окажется "ниже плинтуса" несмотря на "100 ядер". Ну вот это и есть их единственная ниша, замена программными реализациями сложных и дорогих кастомных ASIC — но пока производительности для этого совершенно недостаточно. На CPU и замахиваться-то смешно. Угу. Только тогда было одно ядро с коэффициентом умножения 5 или 6 максимум (для кэша 512), а сейчас их по дюжине на ядро, с коэффициентами умножения под два десятка, плюс прирост IPC. Нет, кэши не зря делают "чем больше, тем лучше", превышение потребностей процессора над способностями ОЗУ не уменьшилось (лениво считать, но как бы не наоборот, кстати)... Без большой и умной системы кэширования современные процессоры превратятся в непристойные тормозисторы. |
|
>Только тогда было одно ядро с коэффициентом умножения 5 или 6 максимум (для кэша 512)
AMD Athlon (K7/Argon) 1GHz (10x100) >а сейчас их по дюжине на ядро По дюжине чего? У K10 по одному каналу памяти на 2 или 3 ядра. >с коэффициентами умножения под два десятка Нет больше внешней системной шины, увеличивающей задержки доступа и ограничивающей ПСП, нет и прежних коэффициентов умножения. У K10 (Thuban) 3300/1333=2,5 штатно. |
А насколько становилось приятнее при переходе на DDR — помните? Ядер на сокет. Прошу прощения, неправильно сказал. У 12-и ядерных серверных процессоров АМД 4 ядра на канал. И очень продвинутая архитектура для работы с памятью других сокетов. С интерконнектом по одной шине PCI-E 8x даже и сравнивать нечего. Латентность по-прежнему определяется частотой следования команд управления. Какая там опорная частота у DDR3? Вот именно поэтому и растут кэши, что пока DDR<много> прочихается и начнет отдавать данные — процессор успеет кучу дел переделать. |
|
Stranger_NN
Честно говоря, я плохо представляю себе сочетание режимов кэширования в такой системе. Сижу тут и думаю — отвечать снова по пунктам или, лучше, дать ссылку на какого-нибудь авторитета и попытаться описать причины (ну не писатель я). Ссылка на Intel Research #1: Single-Chip Cloud Computer (ничего не напоминает? ). А об овчинке там есть таблица.Кратко об L3 кешах от себя. Пару ядер кроссбаром к общему кешу присоединить не проблема. С большим количеством ядер проводов получается многовато, и они греются сильно. В Sandy Bridge Intel перешёл на ring bus. Но с ростом кол-ва ядер одномерной шины к общему кешу перестанет хватать. Тут на смену придут сети типа DDC в Tilera. Рост кол-ва ядер сейчас пойдёт (или уже идёт) по закону Мура (о росте кол-ва транзисторов) — из самого ядра уже больше почти ничего не выжать, используя нынешние технологии. Вы тут так хвалите общие кеши и ccNUMA, но не забывайте об их недостатках. |
|
Buntar
То бишь — революция всё же намечается, в способе организации работы с памятью, по крайне мере |
|
Stranger_NN
>А насколько становилось приятнее при переходе на DDR — помните? Когда DDR стала 2-канальной и выросла до 400МГц эффективных, стало действительно приятнее. До этого DDR существенно выигрывала у SDRAM лишь по скорости записи, а в реальных задачах разница была незначительна. VIA KT266 вообще оказался тормозом, пришлось спешно делать новую ревизию. >И очень продвинутая архитектура для работы с памятью других сокетов. MOESI ещё Athlon MP поддерживали. В Thuban / Istanbul / Magny Cours добавили S1 состояние и возможность использования HT Assist, то есть протокола на основе неполной директории вместо классической широковещалки. Оно-то хорошо, но расплачиваться приходится 1Мб куском T-cache под директорию, так как её размещение в памяти обычно энтузиазма не вызывает. Интел до Нехалема вообще лишь примитивный MESI поддерживал Но поскольку применить расширенный MOESI или директорию им религия/гордость не позволила, они сохранили включающую иерархию кэш-памяти и добавили костыль к MESI, получив MESIF, который не забыли своевременно запатентовать >Вот именно поэтому и растут кэши, что пока DDR<много> прочихается и начнет отдавать данные — процессор успеет кучу дел переделать. 60нс на десктопе (Athlon 64) уже давно. 1Мб кэш-памяти на ядро более чем достаточно, поэтому AMD не стремится увеличивать S-cache свыше этого размера. Если вообще отключить казалось бы большой T-cache, то критического падения производительности не будет. Если же отключить все S-cache при работающем T-cache, то будет очень печально. Да и дело не в количестве транзисторов, а в занимаемой ими площади. Низкоуровневые кэшевые транзисторы обычно очень плотно упаковываются. |
Угу... Вот только какая загогулина: я не могу себе представить коммутатор на 1000 портов, который в большинстве случаев обеспечит отсутствие блокировки по занятости порта назначения, и соответственно — непрогнозируемых задержек. Вероятность блокировки (при произвольном и равномерном потоке запросов к разделяемой кэш-памяти) возрастает пропорционально факториалу (если склероз не подводит) количества ядер. Увы. Более того, я в его реальности — коммутатора кэшей на 1000 портов — вообще сомневаюсь. Это, простите, до охренеть сколько проводов и безумная матрица. Кольцевая шина выбрана неспроста, мы как-то тут (или на хоботе еще?) обсуждали уже, что только кольцо способно дать прогнозируемую задержку обращения и почти линейное масштабирование задержек с ростом количества узлов, и к тому же — минимальное количество проводов.. Коммутатор же с т.з. задержек — великолепен при малой загрузке и отвратителен при большой. В силу последовательной природы множества важнейших алгоритмов процессор из множества слабых ядрышек тоже бесперспективен. Использование MISD векторов из нескольких ядрышек — штука интересная, но в случае циклических алгоритмов прогон "кольца" по всему вектору — дело, без преувеличения, мучительное. Так что от относительно мощных ядер никуда не уйти, все равно. А их количество, по понятным причинам, — будет сравнительно невелико. Далее — см. выше, про топологию. KT266 просто был в принципе неудачен, к самой памяти это отношения не имеет. А с нормальными чипсетами производительность систем выросла очень заметно. Системы с DDR 266 при прочих равных были гораздо приятнее, чем с SDRAM PC133 И в работе и в игрушках.Да. Но я тут больше имел ввиду пропускную способность линков HT, хотя и к ним по вносимым задержкам есть вопросы. Это сколько в граммах тактах? А у кэша сколько? Угу... То-то процессоры с 12 и 14 мегабайтами кэша часто уходят в непропорциональный отрыв на "массивных" задачах... Которых все больше и больше. Прошу прощения за задержку с ответом, — разбирался с новой игрушкой. |
|
Stranger_NN
>Системы с DDR 266 при прочих равных были гораздо приятнее, чем с SDRAM PC133 И в работе и в игрушках.Ох уж эти сказки давно забытых времён...  AMD Athlon (Thunderbird) 1.0GHz; Soltek 75DRV2 и Epox 8KHA+ = VIA KT266A, Soltek 75KAV = VIA KT133A И? >Да. Но я тут больше имел ввиду пропускную способность линков HT, хотя и к ним по вносимым задержкам есть вопросы. Если ОС поддерживает NUMA как следует, то нагрузка на HT шины будет в пределах допустимого. Если не поддерживает, то будет маловато не только пропускной способности HT 3.1, но и QPI. Задержки уж какие есть. >А у кэша сколько? Какого из них? Асинхронный T-cache как-то не блещет. >То-то процессоры с 12 и 14 мегабайтами кэша часто уходят в непропорциональный отрыв на "массивных" задачах... Это преимущественно серверные задачи с большим объёмом обрабатываемых данных в нескольких активных контекстах. На десктопе это неактуально, там типично один "тяжёлый" контекст, ему и 4 метров обычно более чем достаточно. |
Да-да-да.... Тот же гигагерцовый Athlon. На больших разрешениях упор в видеокарту налицо. 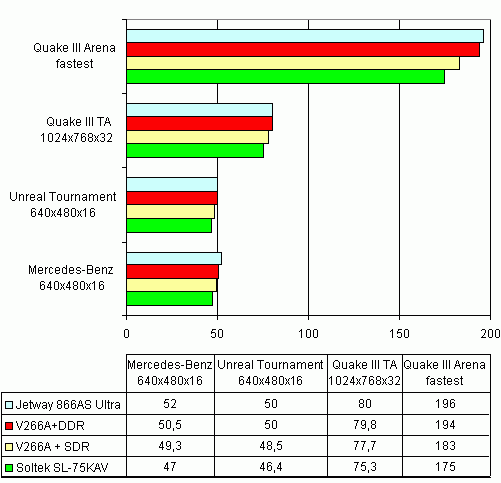 И не в играх тоже: 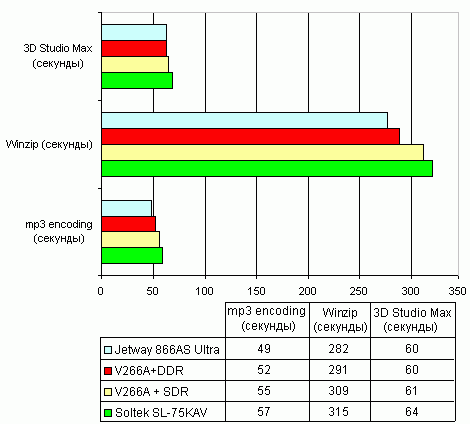 А ведь гигагерцовый процессор — это еще не самый требовательный к памяти потребитель.Когда Intel сумела отбиться от кабального договора с RAMBUS — то от перехода с SDRAM на DDR — эффект получился еще заметнее (график для двухгигагерцового квадропня без HTT): 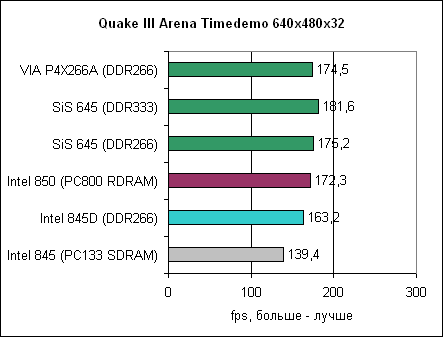 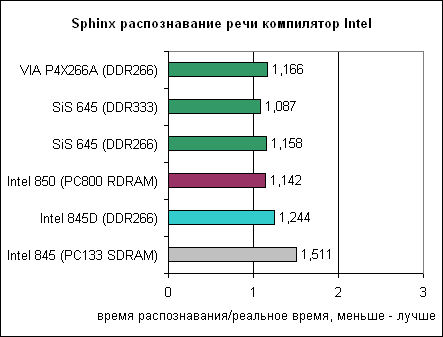 И... Продолжать? Здрасьте. Если мы говорим о поддержке NUMA — то к чему тема про объединение кэшей в единое пространство? Оно по определению не единое со всеми вытекающими из этого следствиями для производительности. Так четырех или одного? И отчего процессоры с большими кэшами третьего уровня и в десктопных задачах оказываются сугубо неплохи. А уж по отзывчивости системы и вовсе.... |
|
>На больших разрешениях упор в видеокарту налицо.
В 640х480 то же самое. Разница в ~10% везде, что и требовалось доказать. Это "гораздо приятнее"? >А ведь гигагерцовый процессор — это еще не самый требовательный к памяти потребитель. 845 был страшным обрезком, чтобы ни в коем случае не конкурировать с 850. Немногим лучше был и 845D, он ведь даже альтернативам от VIA и SiS при прочих равных проигрывал по ПСП, чего с интеловскими контроллерами памяти доселе не случалось. >Если мы говорим о поддержке NUMA — то к чему тема про объединение кэшей в единое пространство? Оно по определению не единое со всеми вытекающими из этого следствиями для производительности. Какое ещё "единое пространство"? >Так четырех или одного? Уже запамятовали, что у Интела во времена Core 2 был общий S-cache на два ядра типично такого размера, если не учитывать бюджетные обрезки? >А уж по отзывчивости системы и вовсе.... Когда говорят об "отзывчивости системы" и это не RTOS, то обычно плацебо. |
|
Asmodeus
Не в ближайшем будущем, но организация работы с памятью будет меняться, скорее всего. 48 ядер Оптеронов на ccNUMA — это уже перебор (32 их же часто работают быстрее — проблема false sharing). Stranger_NN Вот только какая загогулина: я не могу себе представить коммутатор на 1000 портов Я там написал, что интерес к кроссбару (коммутатору) стремительно падает уже при более пары (>2) ядер. При более 4-х обычно не применяется. Бывало извращение SPARC T3 даже с 16-ю ядрами. Но это исключение, скорее, только подтверждает правило. Кольцевая шина выбрана неспроста, мы как-то тут (или на хоботе еще?) обсуждали уже, что только кольцо способно дать прогнозируемую задержку обращения и почти линейное масштабирование задержек с ростом количества узлов, и к тому же — минимальное количество проводов.. Перечитайте моё сообщение. Кольцевые шины давно применяются. В том и проблема, что линейное масштабирование задержек с ростом количества узлов. С 2D сетями масштабирование задержек получается в виде квадратного корня от кол-ва узлов. В многоядерных процессорах кольцевая шина совсем не рулит. В силу последовательной природы множества важнейших алгоритмов процессор из множества слабых ядрышек тоже бесперспективен. "Тратить" транзисторы будущих процессов на кеш предлагаете, как я понял? Причём, на L3 кеш — т.е. сами ядра останутся такими же слабыми, как сейчас. Это перспективно? Огромному кол-ву задач (возможно, большинству) на L3 вообще наплевать, о чём Walter S. Farrell тут тоже пишет. Так что от относительно мощных ядер никуда не уйти, все равно. Откуда в обозримом будущем, вдруг, возьмутся более мощные ядра? Или ничего совсем не делать, пока они не появятся? |
| Новая тема Ответить | Страница 1 из 2 |
[ Сообщений: 57 ] | На страницу 1, 2 След. |
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 0 |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
